Data determines humanity. Societal pursuit of technological innovation and the digitization of human life creates explosive demand for data storage and retrieval. From agricultural revolutions, healthcare discoveries, and political archives, to self-driving cars, protein folding, and neural networks, data is the primary accelerant that helps us discover new solutions to accomplish our goals. It is the fundamental tool that constrains and compels our ability to act with agency and the irreducible input that permits access and gives meaning to our digital and physical lives. Data determines humanity: we must care strongly about how our data is stored, managed, and owned.
The Global Datasphere
Today, over 63% of the global population, or 5+ billion people, use the internet, and this figure will continue to grow at over 10% per year. But the cloud storage market is growing even faster. From 2015 to 2025, the global datasphere—the amount of data created, captured, replicated, and consumed worldwide—is estimated to grow at a CAGR of 58%, with over 180ZB of data created, stored, and replicated by 2025. If you were to stack enough 10-terabyte hard drives to fulfill the world’s data needs by 2025, the stack would literally reach the moon.

Global datasphere size by year. Source: Uygun & Döngül, 2021.
In economic terms, the cloud storage market was valued at roughly $76B in 2021; by 2028, it will reach $390B (a CAGR of 26.2%). Despite such explosive economic growth, market share among cloud storage providers continues to consolidate. As of 1Q22, the 3 largest cloud providers—Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (what I will affectionately call the Big 3)—captured 65% of the cloud computing market(1). The power possessed by centralized cloud storage providers compounds their network effects, reputations, technological infrastructures, and balance sheets such that new competitors are simply unable to compete.
Types of Storage Solutions
- On-Premise
- Centralized Cloud Storage (CCS)
- Decentralized Cloud Storage (DCS)
On-premise storage and CCS providers—the Big 3 (Amazon, Azure, Google) as well as Alibaba Cloud, Box, iCloud, and more—are characterized by their location-centric storage approach. This means information is stored and maintained in a single location (or a small handful of locations), managed in a single database, and operated by a single entity. Both on-premise and CCS solutions suffer from single-point-of-failure risk.
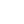
The proliferation of CCS solutions requires an historical glance at the economics of on-premise data storage. At first, users stored data on their own hardware. This meant data was stored and maintained in the same physical location of the entity that wished to store it (such as a company’s onsite data server). I refer to this as Phase I.
The three phases of data storage adoption. Source: Hunter Lampson.
As the network effects of cloud storage enabled cheaper (and oftentimes more secure) (2) storage capabilities, consumers and companies moved to the centralized cloud (Phase II). CCS solutions developed cloud compute, API, and other SaaS offerings, and with it, customers grew. Though centralized solutions were the easiest, cheapest, and most effective options on the market, their fundamental limitations have remained the same: one receptacle is responsible for 100% of an entity’s data. CCS solutions are an improvement from on-premise solutions, but what was once economically optimal has become costly and prohibitive. Today, DCS providers are the cheapest and most secure storage solutions on the market.
Key Weaknesses of CCS Solutions
- Lack of Data Ownership
When users upload data to a CCS provider, they no longer own their data. Apple’s controversial decision (later revoked) to scan iCloud users’ photos is a perfect example of this. Apple boasts strict privacy-protecting policies when data is stored locally (on-premise) on a given hardware product (iPhone, Mac, etc.). But, importantly, the second that a user uploads a single byte of data to iCloud, Apple considers that data to be in their domain—no longer in the domain of the user. This precedent implies that data stored on-premise belongs to the user while data stored in the cloud belongs to the storage provider.
- Prone to Data Breaches & Outages
One need not look far to find massive data breaches among CCS providers. Amazon, Azure, and Google have each suffered from this given their single-point-of-failure structure.
The centralized construction of these providers allows for them to build large walls and provide a higher level of security relative to on-premise solutions. At the same time, the larger and more centralized a database becomes, the more coveted it becomes for an attacker. Data outages, too, are commonplace among CCS solutions. Examples can be seen here: Amazon, Azure, Google.
- Prone to Censorship
CCS providers not only lose data uncontrollably, but they also intentionally remove it. Just a few weeks ago the popular YouTube channel Bankless was terminated with no warning, notification, nor justification. Google, which owns and stores YouTube content on its cloud service, thankfully reinstated the channel, but the capacity that Google and other CCS providers have to terminate the existence of certain data is harmful to society.
- High Costs
Perhaps the most critical drawback of CCS solutions is the high fees. Despite the fact that, over the past 50 years, the cost to store data has decreased by an average of 30.5% per year, CCS prices have been flat for the past ~7 years. This is due to the network effects that CCS providers have accrued. Because of these network effects, the Big 3 have come to dominate the cloud computing landscape. As their collective market share continues to grow, the Big 3 function as an oligopoly with the ability to manipulate prices and shut out new entrants.

Cost of data storage over time. Source: Arweave Yellowpaper.

Cost of data storage over time on AWS, Azure, Google. Sources: AWS, Azure, Google, Hunter Lampson.
The primary reason for the delta between price of storage and the cost of storage is due to the market dominance that CCS providers maintain today. DCS solutions have followed a different path.
DCS Solutions
Building atop the weaknesses of CCS, decentralized cloud storage (DCS) has proven to be a paradigm shift in the data storage landscape (Phase III). DCS solutions enable the utilization of idle hard drive space across a geographically-distributed set of nodes by matching the supply and demand of storage space. This creates a more efficient marketplace that lowers costs and removes the single-point-of-failure risk that persists in both on-premise and CCS solutions. DCS solutions also return data ownership back to users.

Cumulative cost of storing 1 GB per year by platform. Sources: AWS, Azure, Google, Storj, SiaStats, Arweave Fees, File.app, Hunter Lampson.
Though the geographic distribution of data centers and storage nodes is not the only factor that determines how de/centralized a network is, it is a helpful litmus test. Node distribution across space is also an important factor in determining the level with which data can be replicated, retrieved, and secured. Generally, the more nodes in a network, the faster it is retrieved, and the more protected it is from natural disasters (when are we putting storage nodes on the moon?!). Thus, it is important to understand node decentralization as a prerequisite to effective cloud storage.
What makes DCS solutions revolutionary is how decentralized they are in comparison to CCS solutions. There are over 114x more active nodes running on Sia, Storj, Filecoin, and Arweave than there are data centers managed by AWS, Azure, and Google Cloud combined.

Total active nodes by service. Sources: Filscan, Viewblock, Storj, SiaStats, Peterson 2015, Baxtel, Google, Sam Williams, Hunter Lampson.
*Arweave’s node count is difficult to quantify, given that the stats provided by Viewblock count each storage pool as a single storage node. In an offline conversation, Sam Williams, the founder of Arweave, told me that the 59 current storage pools (according to Viewblock), can have hundreds, even thousands, of nodes backing them. Thus, Viewblock underestimates the actual node count by ~10-100x. For this reason, I have used ‘500+’ as the node count, in an effort to be conservative. It is also important to note that active node count is an imperfect metric measurement of decentralization. The sheer number of nodes tells us nothing about who operates the nodes (and how many nodes are operated by each entity).
To borrow from Spencer Applebaum and Tushar Jain, an important distinction among DCS services is the difference between contract-based and permanent storage solutions. Simply put: all DCS services in the market today are contract-based models, with the one exception of Arweave.
Contract-Based vs Permanent Storage Models
Filecoin, Sia, and Storj utilize a contract-based pricing model—the same model deployed by CCS incumbents today. Contract-based pricing means that users pay to store their data on an ongoing basis, similar to how one would pay for a subscription. Despite their nuances, Filecoin, Sia, and Storj compete directly with existing CCS providers.
Arweave, on the other hand, provides a permanent storage model. This means that users pay a single, upfront fee, and, in return, their data is stored permanently. Too often, Arweave is lazily and imprecisely compared to other DCS and CCS providers. The fundamental feature that defines Arweave from its competitors is data permanence.

Conceptualization map of CCS and DCS solutions. Source: Hunter Lampson.
A closer look at Filecoin, Sia, and Storj helps us better understand their similarities and differences in comparison to CCS providers and Arweave.

Key characteristics of DCS solutions. Sources: Filecoin, Storj, Sia, Arweave, CoinMarketCap, Crunchbase.
Filecoin
Filecoin, which launched its mainnet in October 2020, is the most widely adopted and well-funded DCS project in the market today. As of July 12, 2022, Filecoin had a fully diluted market cap of ~$1.19B, with an all-time high of $12.3B. Juan Benet is the Founder and CEO of Protocol Labs, the company behind Filecoin and its underlying technology, the InterPlanetary File System (IPFS). To date, Filecoin has raised $258.2M in funding, the majority of which came via an Initial Coin Offering (ICO) in late 2017.
To understand Filecoin, we must understand IPFS, a peer-to-peer (P2P) distributed system for storing and retrieving data. Built to address the shortcomings of the HTTP-based internet, IPFS uses content-addressing to categorize data, meaning that information is requested for and delivered on the basis of its content, not its location. This is achieved by issuing each piece of data a content identifier (CID) which is generated by hashing the contents of each file, making it immutable. To locate the requested information (represented by a unique CID), IPFS uses distributed hash tables (DHTs) which contain the network locations of nodes that have stored the content pertaining to a CID. When a user requests information from an IPFS node, the node will check its own hash table to see if it can locate (then retrieve) the requested file. If the node does not contain the requested information, it can download the content from peer nodes and deliver it to the user. In this model, information is replicated across many nodes, rather than a single, centralized location that would exist in the HTTP model. This removes the single-point-of-failure risk while improving retrieval speeds, as data is retrieved from multiple peers simultaneously.
IPFS is the communication network through which data is stored and transmitted, and Filecoin is the economic system built on top. IPFS alone does not incentivize users to store the data of others: Filecoin does. This is accomplished with two unique proof mechanisms: Proof-of-Replication (PoRep) and Proof-of-Spacetime (PoSt). PoRep is run once to verify that a storage miner has the content they say they do. For every on-chain PoRep there are 10 SNARKs (Succinct Non-Interactive Argument of Knowledge) included, which prove contract completion. On the other hand, PoSt is run continuously to prove that storage miners dedicate storage space to the same data over time. The on-chain interaction required to validate this process is data-intensive, so Filecoin uses zk-SNARKs (Zero-Knowledge Succinct Non-Interactive Argument of Knowledge) to generate these proofs, compressing them by up to 10x.
Sia
Of the four DCS protocols discussed, Sia was the first to launch and did so in June 2015. Founded by David Vorick and Luke Champine at HackMIT in 2013, Sia has seen strong user traction, boasting a fully diluted market cap of ~$190M, with an all-time high of $2.97B.
Sia was launched by Nebulous Labs, which was established in 2014. Sia, in a similar manner to Filecoin, divides uploaded data into composite parts (in this case: fragments) and disperses them to distributed hosts around the globe. Unlike Filecoin, Sia achieves this via a different Proof-of-Storage (PoS) mechanism. This proof requires hosts to share a small percentage of randomly selected data over time. This proof is validated and stored on the Sia blockchain, and the host is rewarded with Siacoin.
Storj
Storj, like Filecoin and Sia, has gained significant traction since its launch in October 2018. Storj differentiates itself from Filecoin and Sia in that it does not rely on blockchain consensus to store data. Instead, Storj relies exclusively on erasure encoding and satellite nodes to store data, to increase data redundancy and reduce bandwidth usage. Storj’s exclusive use of erasure encoding means data durability—the probability that data remains available in the face of failures—is not linearly linked to the expansion factor—the additional cost required to reliably store data. Thus, on Storj, higher durability does not require a proportional increase in bandwidth. Given node churn—the rate at which nodes go offline (or leave the network)—erasure coding could prove to be valuable over the long term, given that it requires less disk space and less bandwidth for storage and repair, despite its increase in CPU runtime.
Storj deviates from Filecoin and Sia through their network architecture and pricing mechanism as well. On Storj, pricing is determined by satellite nodes that intermediate storage users (including applications) and storage nodes. Satellite nodes are responsible for negotiating pricing and bandwidth utilization. Thus, rather than relying exclusively on free-market activity, Storj’s pricing model is subject to centralizing forces, as Satellite operators represent a potentially centralized intermediary between nodes and end-users.
Storj also natively integrates with Amazon S3, meaning that existing Amazon S3 users are able to migrate to Storj and use basic features without changing much of their codebase. This may reduce the friction associated with leaving the Amazon S3 ecosystem.
Arweave
In contrast to Filecoin, Sia, and Storj, Arweave provides permanent data storage. Launched in June of 2018 by Sam Williams, CEO, and William Jones, Arweave has reached a fully diluted market cap of $726M, as of July 12, 2022, with an all-time high market cap of $2.88B.
Arweave seeks to provide permanent data storage in a decentralized manner for a one-time fee. This is accomplished via Arweave’s endowment mechanism. Given that the cost of data storage has decreased by 30.5% per year for the past 50 years, Arweave assumes that storage purchasing power of a $/GB today is more costly than a $/GB in the future. This delta enables Arweave’s endowment pool. The ‘principal’ is the upfront fee paid by the user, and the ‘interest’ is the increase in purchasing power over time denominated in a currency today. Arweave’s conservative assumption of a 0.5% decrease in storage price per year enables the long-term viability of the endowment pool.
Arweave’s current cost of ~$3.85/GB reflects the terminal value of data storage. In the short term, Sia and Filecoin (and even the Big 3) are cheaper. But over the long term, Arweave becomes a more sensible choice. Even in the short term, users pay a premium for something nobody else can offer: data permanence. For some, the cost of permanent storage is relatively inelastic because some files, such as NFTs, require it.
Arweave is powered by the blockweave, a data structure similar to a blockchain, where each block is linked to both the previous block and the recall block. The recall block is any block that has been previously mined other than the most recently mined block. Thus, Arweave’s structure is not just a chain that links consecutive blocks together—it is a weave that links the current block to both the previously mined block and another block at random, the recall block.
In order to mine a new block, and receive the mining rewards, the miner must demonstrate that they have access to the recall block. Arweave’s Proof-of-Access (PoA) mechanism guarantees that, for every newly mined block, the data from the recall block is also included. This means that to store new data, miners must simultaneously store existing data. PoA also incentivizes miners to replicate all data across nodes equally. When less-well-replicated blocks are chosen as the recall block, miners with access to it compete among a fewer pool of miners for the same reward. Ceteris paribus, miners who store less-well-replicated blocks will receive a greater reward over time.
Built atop the blockweave is the permaweb—similar to the world wide web today, but permanent. Arweave’s bockweave is the base layer that powers the permaweb; the permaweb is the layer that users interact with. Given that Arweave is built on HTTP, traditional browsers have access to all data stored on the network, resulting in seamless interoperability.
Traction
Though DCS solutions may be ideologically superior to CCS solutions in principle, they ought to be valued on the basis of their usefulness in practice. We can measure the traction of each project by examining the following:
- Data Stored
- Node Distribution
- Search Interest
- Ecosystem Strength
- Demand-Side Revenue
1. Data Stored
Demand is measured directly by examining data storage volume over time and is considered to be a primary KPI for DCS providers. By this metric alone, Filecoin dominates; as of writing, Filecoin stores over 90% of the DCS datasphere, up from 82.8% just 90 days ago.

Proportion of DCS datasphere stored. Sources: Storj Stats, SiaStats, Viewblock, File.app, Hunter Lampson.
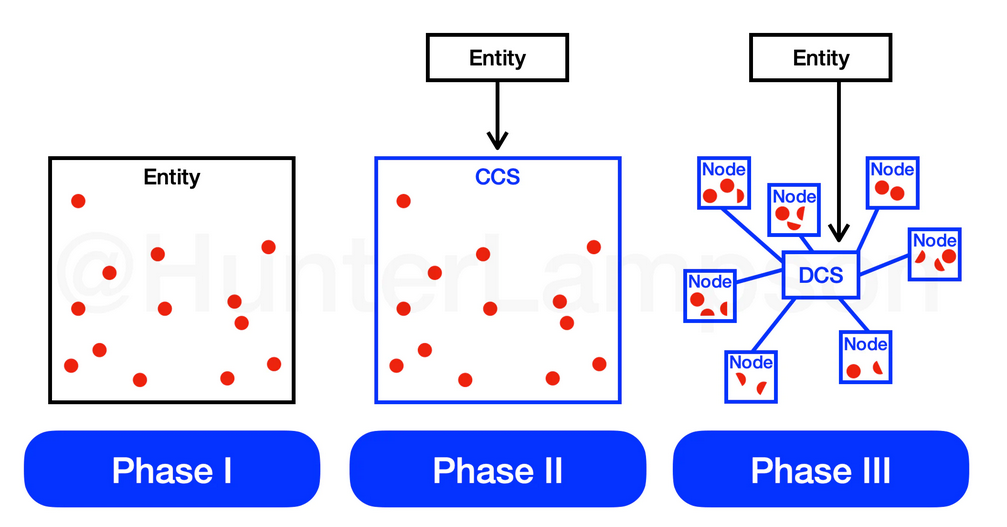
Not only does Filecoin store the most data: it is also growing the fastest. In the past 90 days, Filecoin has grown the data stored on-platform by 112%.
Data storage growth (past 90 days). Sources: Storj Stats, SiaStats, Viewblock, File.app, Hunter Lampson.
Given that these are storage protocols, the volume of data stored is an important metric, though it has severe limitations. Data storage volume tells us nothing about protocol revenue nor the data itself (how valuable it is, what its function is, how long it will be stored for, etc.). Among both DCS and CCS providers, there is an ongoing debate about how to characterize stored data because not all data is valued (and treated) equally. Some data is more important than other data. It is possible that users may bifurcate their storage providers based on this metric, so the sheer volume of data stored only paints a partial picture.
Data storage volume also lacks context about how the data will contribute to the protocol’s demand-side revenue. This is especially problematic when considering Filecoin. Filecoin is the only DCS service that essentially offers storage for free. For this reason, users may store data with Filecoin because of its current pricing (more on this later…). Though I have been hard pressed to find published sources on this (for obvious reasons), anecdotally, countless builders and researchers in this space—all of whom I deeply respect—have told me that Filecoin tends to partner with large institutions to offer free storage in order to manipulate their storage volume metrics. In theory, then, Filecoin could store infinitely more data than any other DCS protocol and still generate zero demand-side revenue.
2. Node Distribution
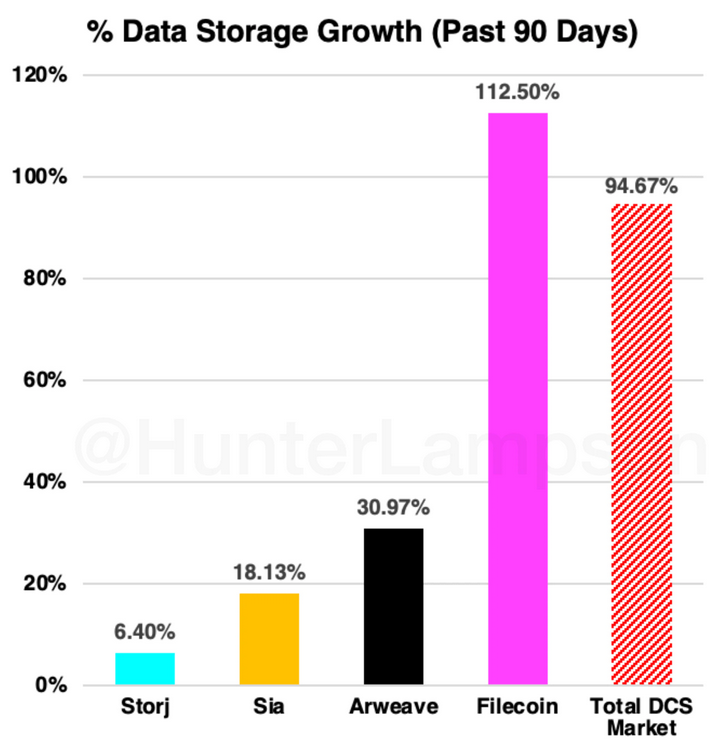
Though data storage volume is a direct measurement of storage demand, we can look at indirect measurements as well. Node distribution is important to understand as it highlights the geographic component of demand- and supply-side participants. We can assess this by observing the geographical distribution of 1) storage nodes and 2) search interest.
The more dispersed the distribution of storage nodes is across space, the better. Higher dispersion leads to greater decentralization (usually) and a lower time-to-retrieval from node to end-user. Higher dispersion also mitigates the risk of unrecoverable data loss (often due to environmental factors, like natural disasters). Ideally, nodes would not be arbitrarily dispersed across space but would correlate with storage demand across space (likely equivalent to technological saturation times population density). Given the fact that the U.S., China, and Europe exhibit the highest concentrations of storage demand, we would expect them to possess the highest concentration of storage nodes. It thus makes sense that node distribution among both CCS and DCS solutions is concentrated in the U.S., Europe, and China. The fact that DCS node distribution is similar to CCS storage center distribution is a positive signal that DCS solutions have achieved an important level of market maturity.
Geographical distribution of DCS nodes. Sources: Filscan, Viewblock, Storj, SiaStats, Sam Williams.
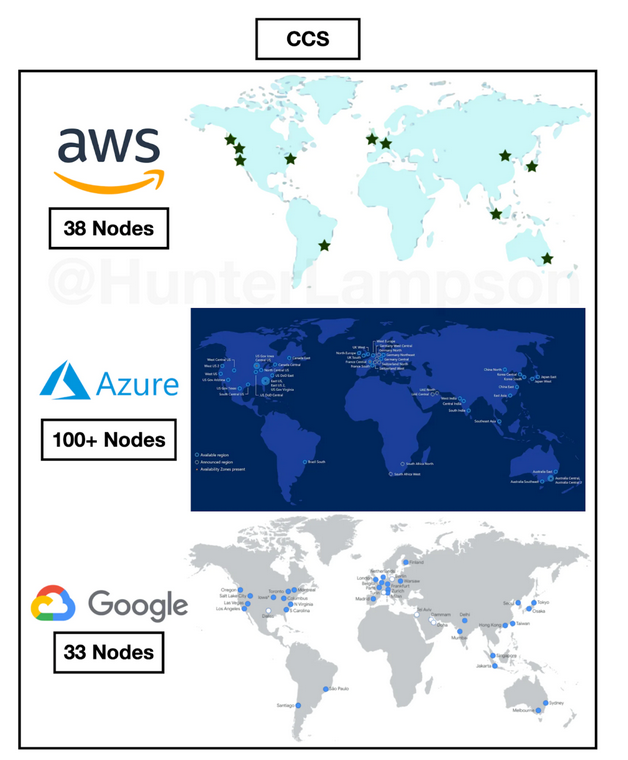
Geographical distribution of CCS nodes (data centers). Source: Peterson 2015, Baxtel, Google.
3. Search Interest
If we think of node distribution as the distribution in DCS supply, we can, at least partially, consider search interest distribution as the distribution in DCS demand. (This assumption is based on the fact that, for each search of a DCS solution, there is a greater likelihood that the searcher is a user of storage space, rather than a supplier.)
According to this metric, it is clear that Filecoin currently has, by far, the highest search interest dominance worldwide, relative to Storj, Sia, and Arweave. Thus, one might assume that Filecoin experiences the highest relative demand.
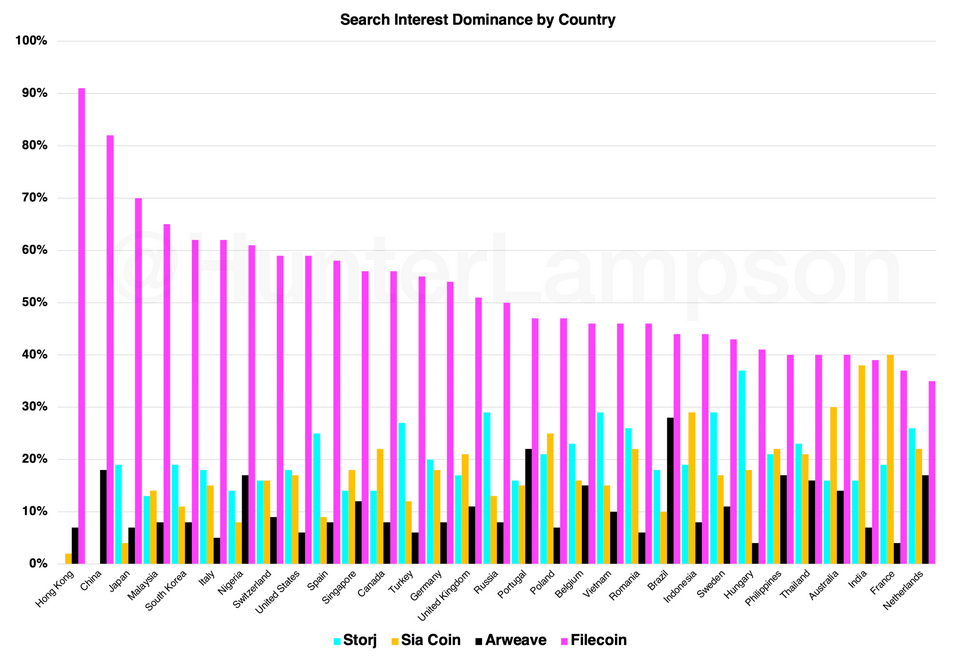
Relative search interest dominance by country. Source: Google Trends. Note: I use the term 'Sia Coin' rather than 'Sia' in order to avoid electropop/'Chandelier' fans :)
These assumptions are based on supply and demand metrics today, but looking at the past paints a similar picture. Since mid-2021, Filecoin has remained the most-searched-for DCS solution. Notably, Filecoin search interest was nearly eclipsed by Arweave in August 2021 and by Storj in November 2021 and December 2021.
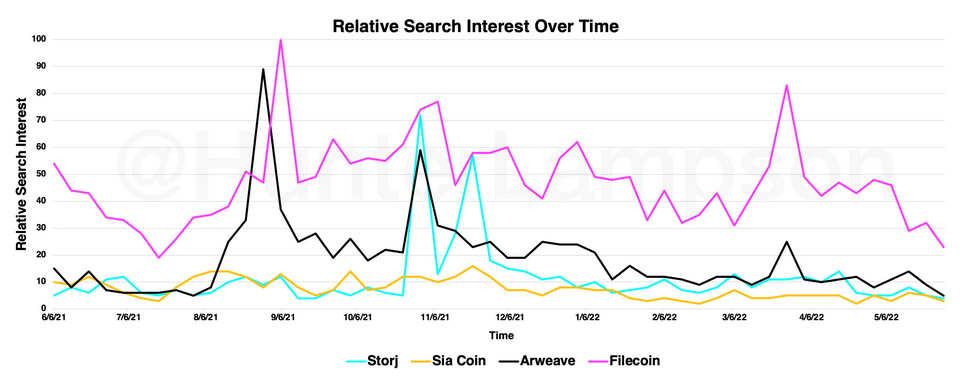
Relative search interest over time. Source: Google Trends.
Though search interest can be a useful metric, it has severe limitations. What this metric shows us is how individual users engage with Google to obtain information about each project. Search interest shows us nothing about actual protocol demand.
The argument could easily be made that, since Filecoin has raised the most funding to date, they likely have the most money to spend on marketing. Then, maybe the marketing budget alone accounts for the search interest variability among each project. Perhaps search interest dominance is a better predictor of funding received than protocol demand—who is to say? Further, Filecoin’s ownership of easily understandable, keyword-heavy domains, such as Web3.Storage and NFT.Storage, may also elicit skewed data. It may be the case that users who search for “Web3 Storage” come across Filecoin’s services, solely based on SEO and the domains they own.
Another limitation of search interest variability is its potential to be highly uncorrelated with storage demand. For example, if a user intends to move hundreds of TBs of data to a DCS provider, their search engagement (one search) will not reflect their actual storage demand. It is also possible that extraneous variables, such as the degree to which CEXs (Centralized Exchanges), like Coinbase, for example, market these individual tokens, play a significant role here.
4. Ecosystem
Because DCS solutions exist on the infrastructure layer, their ecosystems often represent user demand, as their users (consumers, companies, developers) get to choose which ecosystem to use or build on. Ecosystem strength is derived from 1) the projects built on top of the protocol and 2) the existing projects they partner with. Filecoin has the most robust ecosystem given the maturity of their partnerships and the rate at which new projects are added. Over the past ~18 months, Filecoin’s ecosystem has grown from 40 projects to well over 300. Filecoin boasts an impressive cohort of partnerships, some of which include: Chainlink, Polygon and Polygon Studios, The Graph, Near, ConsenSys, Brave, ENS, Flow, Hedera, ChainSafe, Ceramic, Livepeer, Audius, Decrpyt, MoNA, and Skiff.

Filecoin ecosystem. Source: Messari.
To help develop their ecosystem, the Filecoin Foundation invests heavily in its ecosystem and grant programs. Protocol Labs, the team behind Filecoin, has made 46 direct investments to date, deploying over $480M into ecosystem projects including Decrpyt, Syndicate, ConsenSys, and Spruce.

Protocol Labs investments over time. Source: Crunchbase.
Second to Filecoin’s ecosystem is Arweave’s. While Filecoin has nearly 300 partnerships, Arweave has roughly 60. Though many of these partnerships could benefit from both platforms simultaneously—for example, Mirror and Skiff could offer the services of both Filecoin and Arweave to their users—other projects, like Solana, are unlikely to use both platforms. This means many of the most critical web3 infrastructure projects—protocols, dApps, NFT platforms—will find product-market fit and ideologically align themselves with either Filecoin or Arweave, depending on the specific use case. The strength of each ecosystem will play a vital role in the long-term viability of each platform, so the ability to win over the hearts and minds of new and existing builders is paramount.
Notably, Arweave’s ecosystem, relative to Filecoin’s, has a higher concentration of net new projects built atop the platform—as they depend on the technology to subsist—rather than existing projects that selectively leverage the technology. This may also explain why Filecoin is partnered with more mature projects. It is not that Filecoin’s partnerships have grown faster and have been more successful, it is that Filecoin has partnered with companies (like Cloudflare and Opera) that have been around longer. In contrast, Arweave generally partners with early-stage companies that are building atop the network from scratch. A few of Arweave’s notable partnerships include Solana, Polkadot, The Graph, Mirror, Bundlr, Glass, KYVE, Decent Land, and ArDrive.

Arweave ecosystem. Source: @axo_pas (on Twitter).
Arweave has deployed nearly $55M into 15 ecosystem projects since 2020, including Mask, Fluence, and Pianity. Through their Open Web Foundry accelerator program, Arweave helps developers build permaweb apps and has previously invested via their community-run ecosystem fund, ARCA DAO.
Sia and Storj have smaller ecosystems, with roughly 30 and 13 projects, respectively. Despite the smaller ecosystems, Sia and Storj boast exceptional partnerships. Some of Storj’s partners include CoinMarketCap, Crypto.com, Kraken, Filebase, Render, Akash, and Quant, while Storj’s partners include Microsoft Azure, Fastly, Couchbase, and Pokt. Importantly, Storj’s strategy is built around capturing existing Amazon S3 users, including large, incumbent corporations. For this reason, many of Storj’s partnerships may refuse to be publicly listed. Storj’s partners may not see any benefit in being listed as such. In contrast, new web3-native projects built atop Arweave, for example, may indeed benefit from being listed as a partner to signify their immersion in the ecosystem. The differing publicity incentives make ecosystem comparison challenging, as we lack access to the full dataset.
Today, Sia is used most predominantly by Filebase, the first Amazon S3-compatible dApp (decentralized application), and also by Arzen, a consumer-focused decentralized storage app.
5. Demand-Side Revenue
Data storage volume may be the most direct measurement of user traction, but demand-side revenue measures the value of user traction—or the project’s ability to monetize user traction. As Sami and Mihai explain in their piece on Filecoin’s revenue model, demand-side revenue is a helpful metric for infrastructure projects, as it measures the fees people pay to use the network (in this case: the fees paid to store data). Importantly, demand-side revenue excludes block rewards paid to miners.
While demand-side revenue data is available for Arweave, Sia, and Storj on The Web3 Index, demand-side revenue data for Filecoin is hard, if not impossible, to find (if anyone can find this data, I would love to see it). For this reason, we cannot include Filecoin in a demand-side revenue comparison.
What we do know about Filecoin’s revenue is that, despite the growth of data stored on their platform, their revenue has remained flat. This is likely due to two reasons: first, the HyperDrive update increased storage onboarding rates by 10-25x, resulting in lower demand for blockspace (as we will see later, this hurts Filecoin’s token value). Second, to store more data without generating higher revenue signals that Filecoin essentially stores data for free. Miners are thus compensated with an unsustainable block reward—roughly 20.56 FIL per block, as of writing—which will decrease over time. In the not-too-distant future, Filecoin will need to raise storage prices to incentivize miners to participate in the network.

Filecoin's protocol revenue has remained uncorrelated to ecosystem growth. Source: Messari.
For Storj, Sia, and Arweave, however, we can see demand-side revenue generated over the past 90 days.
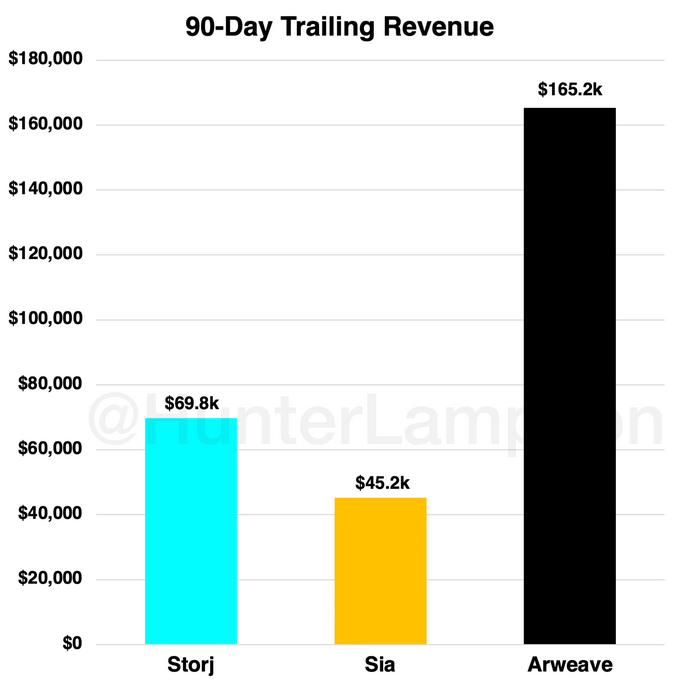
Demand-side revenue for Storj, Sia, Arweave (past 90 days). Source: The Web3 Index.
Because Filecoin, Sia, and Storj are contract-based (temporary) solutions, where users pay to store data on an ongoing basis, we can assume that a nonzero amount of their demand-side revenues are recurring. By contrast, we can assume that 100% of Arweave’s demand-side revenue is nonrecurring, given that users pay once to store data forever. This means that the only way for Arweave to generate demand-side revenue is to store net new data. This presents a significant challenge for Arweave and reminds us of the inadequacy of comparing Arweave to its DCS counterparts.
What may prove to be a moat—or a competitive disadvantage—is the variance in demand-side revenue efficiency (roughly equal to price) among DCS platforms. I define demand-side 'revenue efficiency’ as demand-side revenue generated per byte of data stored. While, over the past 90 days, Storj and Sia have generated demand-side revenues of $96.50 and $89.90 per TB uploaded, respectively, Arweave generated ~$10,200 per TB uploaded. This pricing model is another fundamental difference between Arweave and its DCS competitors: Arweave charges a premium for a functionally distinct service. This also means that Arweave can store up to ~113x less data and still generate the same demand-side revenues as its DCS competitors. This suggests that Arweave should not be expected to store the same amount of data as other solutions because both its service and pricing mechanism is incomparable.
- Token Valuation
- Methodology
Storj, Sia, Arweave, and Filecoin are best understood as a combination of 1) utility tokens (gift cards) and 2) mediums of exchange (currencies). Utility tokens are valued on the basis of their expected future utility; currencies are valued based on supply and demand. Holders of utility tokens are able to redeem them in exchange for a service—in this case, cloud storage. The ability to redeem a utility token for a specified service makes it similar, in structure, to a traditional gift card or voucher. But, unlike gift cards and vouchers, utility tokens are programmatically supplied and autonomous while gift cards and currencies are commercially or governmentally supplied and (almost) always issued in a different currency (usually fiat). Programmatic supply guarantees a specified supply schedule which allows us to calculate, with precision, token supply over time. (The recent CPI print of 9.1% shows us how powerful programmatic monetary supply can be.) We use this, in conjunction with traditional monetarist theory, to derive each token’s intrinsic value.
To be clear: I am interested in valuing token price over time using traditional monetary theory and a discounted cash flow analysis. I am not attempting to value the protocol itself (i.e. total revenues generated [though revenues matter…]), nor the profits of storage miners or storage suppliers. I also recognize the extraordinary cultural value these protocols generate, especially as they (inevitably) become public goods. That said, each protocol’s token price may not take these into account, so I don’t either.
First, an important distinction: traditional public securities (i.e. $AAPL: Apple) and tokens (issued by Protocols) represent different things. Though Protocols generate asset flows, they do not generate cash flows the way Apple does*.* Thus, tokens should not be conflated with public stocks. Tokens represent the right to utility/transact; public equities represent ownership. (Tokens can represent more than the right to utility/transact—they can include governance rights, for example.) To value the price of a token over time requires the inclusion of different mechanics: both monetary theory and a discounted cash flow analysis.
Token Valuation Model
*The model I reference is linked here: Token Valuation Model - Arweave Example*
The principal framework I employ to value token prices over time is Chris Burniske’s model from his seminal piece, Cryptoasset Valuations. Chris argues that, instead of modeling a traditional DCF, one should maintain the same structure and substitute cash flows with the equation of exchange, allowing us to derive each token’s current utility value. Then, we apply a discount rate on the future utility value to derive the intrinsic value today.
The substitute—the equation of exchange: MV = PQ—helps us incorporate the currency-like nature of tokens. As Chris (and countless others) has acknowledged, this model has its limitations (all predictive models do), but it’s likely the best we’ve got. Given the lack of a perfectly efficient market and the wide margin of error inherent in predicting the future, this model is best used to illustrate the various levers that produce a token’s value.
As Chris writes, “A cryptoasset valuation is largely comprised of solving for M, where M = PQ / V. M is the size of the monetary base necessary to support a cryptoeconomy of size PQ, at velocity V.”
Token Valuation Model: Inputs
To estimate M, V, P, and Q, I will use the below:
Mathematically-Derived Inputs
- Max Supply
- Float
- Float CAGR
- Storage Cost ($/GB/Year) or ($/GB)
- Storage Cost Decline/Year (CAGR) (*)
- Datasphere Size
- Datasphere Growth/Year (CAGR)
(*)This is derived from the average decline in storage cost ($/GB/Year) per year among the Big 3 over the past decade, which can be seen below (Figure 20):

Data storage cost and CAGR for AWS, Azure, Google. Sources: AWS, Azure, Google, Hunter Lampson.
Subjective Assumptions
Percent of tokens hodl’d (% of public supply not in float)
I assume that, in 2021, 50% of tokens are hodl’d. This assumption is derived from the fact that, historically, roughly half of Coinbase users have viewed Bitcoin as strictly an investment, while the other half have viewed it as a transactional medium.
Percent change of tokens hodl’d/Year
I assume that the percent of tokens hodl’d will decrease by 1% per year, starting in 2022. As the market approaches equilibrium, there is less potential for value accretion, so the number of tokens in the float will increase (as % of tokens hodl’d decreases). This is incredibly difficult to estimate—again, it is best understood as a lever that contributes to token valuation.
Velocity
I assume the velocity of each token is 20. Given that Bitcoin’s velocity has historically been ~14, I use 20 here to be conservative.
TAM (as % of Global Datasphere)
I assume that Arweave can address 10% of the global datasphere, while Filecoin, Sia, and Storj can address the other 90%. Permanent data storage is a net new market, so it is difficult to determine the % of the existing datasphere it can address, so I use 10% here, in hopes of being conservative. Temporary data storage—the predominant storage solution today—necessarily makes up 100% of the datasphere. If we assume that 10% of the existing datasphere will transition to a Arweave, then Filecoin, Sia, and Storj are left to address the other 90%.
**Maximum % of TAM Acquired
**I assume that the maximum % of TAM acquired is 1% for Arweave, Sia, and Storj. Thus, I assume that Arweave captures 1% of 10% of the global datasphere (a total of 0.1% of the global datasphere for Arweave and 0.9% of the global datasphere each for Sia and Storj). I assume that Filecoin captures 25% of its available TAM (25% of 90% = 18% of the global datasphere) given its traction and maturity.
**Inflection Point
**I assume that 2024 is the year each network reaches its inflection point—the year when 10% of its Maximum % of TAM Acquired is achieved. This is nearly impossible to predict—another illustrative lever.
**Saturation/Year
**I assume that Saturation/Year—the number of years it takes for the network to go from 10% to 90% of its Maximum % of TAM Acquired—is 10 years for Arweave, Sia, and Storj, and 4 years for Filecoin. Another impossible prediction.
**Discount Rate
**I assume a discount rate of 40%, an industry standard for assets of this risk level.
A condensed view of all fixed and variable mathematically-derived inputs and subjective assumptions is below:

Condensed view of fixed and variable mathematically-derived inputs and subjective assumptions used in the token valuation model. Sources: CoinMarketCap, Uygun & Döngül, 2021, Chris Burniske, Hunter Lampson.
On Filecoin’s Differing Inputs:
Cost Decrease of Data Storage (CAGR) = 0%
Assumed Storage Cost ($/GB/Year) = $0.002/GB/Year
In the table, I explicitly label Filecoin’s Cost Decrease of Data Storage (CAGR) and Assumed Storage Cost ($/GB/Year) as an extremely subjective assumption, even though explicit data on this is available. I do this because Filecoin’s current pricing is too cheap to be sustainable.
First, let’s start with Assumed Storage Cost ($/GB/Year). Currently, the storage cost on Filecoin is ~$0.0000017/GB/year, or 0.0011% of the cost to store on a Big 3 provider. As I discuss above, Filecoin’s pricing model is unsustainable, as it is massively subsidized by block rewards. Since their $200M+ Initial Coin Offering, Filecoin has subsidized the cost of storage on their network. As they move away from subsidization, we can expect their storage costs to increase from current levels. Ceteris paribus, an increase in storage cost, with fixed demand, makes $FIL more valuable (as with any token), but we can assume that as Filecoin inevitably raises prices, the demand for storage on their network may decrease, lowering the intrinsic value of $FIL.
It is hard to say how the team will execute on raising prices, even if prices remain lower than the Big 3. If we run this model with the current pricing of ~$0.0000017/GB/year, the 2022 intrinsic value is ~$0.00/FIL, another indication that today’s pricing model is unsustainable. Thus, I have estimated Filecoin storage cost to be $0.002/GB/Year (100x cheaper Big 3 prices) over the next 10 years (assuming a Cost Decrease of Data Storage [CAGR] of 0%). This maintains Filecoin’s competitive pricing—making them 100x more cheaper than the Big 3 solutions—while providing significant value to their token price. Consider this input a personal expectation, or even requirement, for Filecoin to be sustainable.
Token Valuation Model: Outputs
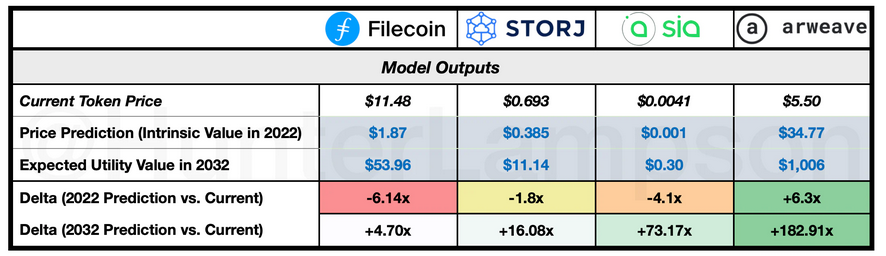
Token valuation model outputs. Sources: CoinMarketCap, Hunter Lampson.
Ceteris paribus, the levers of the model function as follows:

Illustration of various levers that produce a token's value. Source: Hunter Lampson.
This table refers to the general outputs given a change in each lever, rather than a guarantee that, as a lever increases/decreases to an arbitrarily high/low number, the output will always be true. For example, consider velocity: on average, as velocity increases, token price falls. But an arbitrarily low level of velocity, such as a velocity of 0, would mean tokens change hands 0 times per year, and therefore require 0 monetary base to fulfill the ecosystem. That said, by avoiding the tail-ends, the general trends referenced in the table are useful.
Findings
Arweave’s economics are the most defensible, driven by the relatively low supply of $AR tokens and the relatively high storage cost ($/GB). This partially builds on my earlier conclusion that Arweave is the most demand-side revenue efficient of the DCS offerings, meaning it can store 113x less data and generate the same demand-side revenues as its counterparts. Further, my assumption that Arweave captures 0.10% of the global datasphere is conservative enough to be reasonable. If this is achieved, the 2032 token price is predicted to be up +182.91x compared to today’s levels. While Arweave’s high relative pricing may strengthen its unit economics, it may be the Achilles’ heel that stifles user adoption. Users will ultimately determine if Arweave’s services are worth the price premium.
Even if we assume users are willing to pay this premium, in theory, they must be convinced to use the product in practice. Because Arweave’s offering is fundamentally different from its competitors, the switching cost may be too high and the services too distinct to win over net new users. Despite Arweave’s potential upside, the high costs, and reliance on a net new market, could prove to be insurmountable hurdles. As discussed earlier, the only way for Arweave to generate demand-side revenue is to store net new data. On the surface, Arweave does not appear to have the luxury of recurring demand-side revenue per bit of data—something all CCS and DCS competitors benefit from. Instead, I would argue that Arweave benefits from involuntary recurring demand-side revenue. Rather than charging users in perpetuity, Arweave receives ‘permanent recurring demand-side revenue’ upfront. This may prove to be one of Arweave’s most valuable endowment mechanisms.
Currently, Filecoin’s economics are the least defensible, driven by their low pricing. Given a fixed token supply, the lower the cost of a utility becomes, the smaller the monetary base must be to support it. This perspective frames low pricing as a negative attribute of the token value, rather than a positive. It may be equally likely that Filecoin’s low pricing serves as the foundation for a flywheel of adoption. Low pricing may also serve as Filecoin’s key differentiator, which may function as a necessary moat.
What concerns me, however, is the important role that pricing power will play in determining Filecoin’s future. As Tushar and Spencer have argued, Filecoin (and Sia, and Storj) are competing directly with the Big 3 over the temporary storage market. To enter a price war with the Big 3 could be catastrophic. If Filecoin can maintain low pricing—without unsustainable subsidization—its maturity, ecosystem strength, and industry-wide clout may position it as the most capable challenger to the Big 3. If it comes down to a price war—which may be inevitable—things could get ugly.
According to the model, Sia’s token economics make it ~4.5x more valuable than Storj, based on the delta between current pricing and 2032 price predictions. Oftentimes, Sia and Storj are lumped together (as I’m doing now…) as the younger sibling tokens of Filecoin. Given their less robust ecosystems, it is difficult to envision a near future where Sia and/or Storj have superseded Filecoin’s dominance in this space. Despite this, the token economics of Sia and Storj are more attractive than the token economics of Filecoin. Pricing power is and will continue to be integral to token valuations and the long-term viability of each project.
Limitations & Thoughts for Future Research
Cloud storage ≠ cloud compute. As Christine Deakers has noted, many cloud storage users simultaneously use cloud computing on the very data they store. DCS solutions must address this. Filecoin has begun building its virtual machine—and other DCS solutions are likely to follow.
DCS solutions need more integrations. As Mark Gritter has pointed out, most IoT applications need not only distributed storage but distributed databases. If DCS solutions do not natively integrate with conventional time-series databases, this may be a major obstacle to adoption.
DCS solutions should allow for location selectivity. An example Mark Gritter has mentioned is self-driving cars. The stream of sensor data that autonomous cars collect must be stored in a distributed manner in order to achieve the lowest possible latency. DCS solutions may not be well-positioned to address this use case if data uploaders (the cars and car companies) are unable to choose nearby locations to store their data.
Notes
(1) Though cloud computing is different from cloud storage, we can reasonably make a set of assumptions: first, companies (such as the Big 3) that provide the service of cloud computing tend to provide this service on the very data they store. Said differently: customers generally use both compute and storage services in conjunction with one another on a single platform. Second: we can assume that, as cloud companies capture more market share, they benefit from better unit economics at an increasing rate. The larger a company gets, the more effective it can be in negotiating hardware pricing, which drives costs for customers down, and onboards more users, further increasing its negotiating power. So, when I mention that the Big 3 capture 65% of cloud compute market share, we can assume that they capture a similar amount of cloud storage market share.
(2) Throughout this piece, I use the terms ‘secure’ and ‘security’ to describe data that is highly replicated across a distributed set of nodes, which results in higher data redundancy, more consistent uptime, and a decreased likelihood of both censorship and single-point-of-failure risk.
From:https://hunter.mirror.xyz/_04DQ0AHbWCZ1tQxokM1b4bgDEpQ2paukOzEI_w_Ktk